Feeding a SQL server very fast

I was wondering how fast can i insert data in a SQL server from a single SQL script. I though that this will be easy to find out, but i ended up trying a bunch of ways and some of them gave unexpected results. So i decided to write a short article comparing all i tried.
The scripts used can be found here.
Table of contents
Disclaimer
- I’m not by any means, an expert on SQL. So take everything with a grain of salt.
- The time measures are from a very noisy machine and the results may fluctuate greatly from each run, I wouldn’t trust differences on less than 1~2 seconds.
Environment information
- Computer: SteamDeck AMD Custom APU 0405 2.80Ghz 4 cores/8 threads. RAM 16GB LPDDR5.
- Operating system: Windows 10
- Database engine: Microsoft sql server 2019 running in a docker container, with the default configuration.
Target example
For this experiment, i will be using the AdventureWorks 2019 sample database provided by Microsoft, it can be found here.
We could test just doing a lot of inserts into one table, but in order to make this a more realistic scenario, I’m gonna decide some constrains to the problem.
We have the following 2 tables:
Production.ProductModel
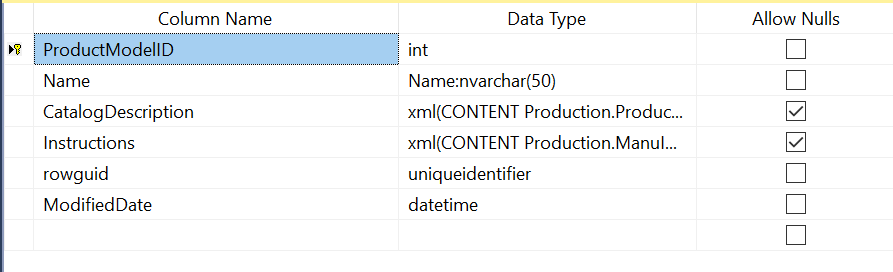
Production.Product
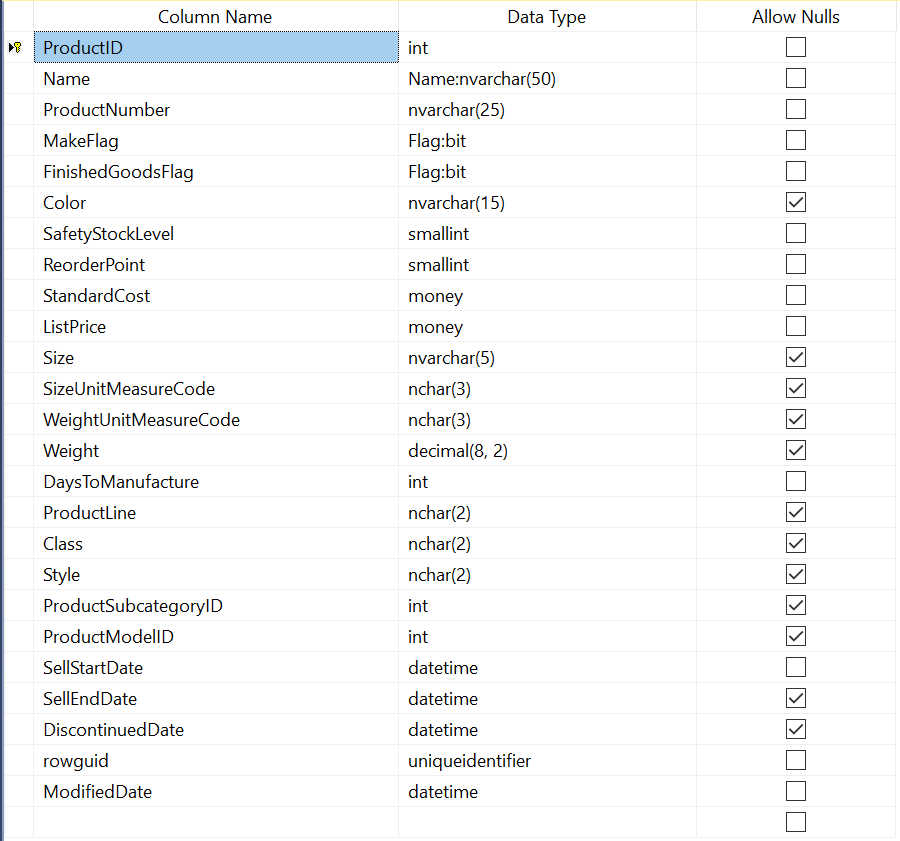
We need to insert records with the following structure:
- ProductModelName: Goes to Production.ProductModel as Name.
- CatalogDescription: Goes to Production.ProductModel.
- Instructions: Goes to Production.ProductModel.
- ProductName: Goes to Production.Product as Name.
- ProductNumber: Goes to Production.Product.
- SafetyStockLevel: Goes to Production.Product.
- ReorderPoint: Goes to Production.Product.
- StandardCost: Goes to Production.Product.
- ListPrice: Goes to Production.Product.
- DaysToManufacture Goes to Production.Product.
As you can see, Production.Product holds a foreign key to Production.ProductModel, so we have to insert the ProductModel’s data first, retrieve the ID and then insert the Product’s data with the corresponding foreign key.
The data that we are trying to insert could be already on the database, so we have to update the rows if Production.ProductModel.Name or Production.Product.ProductNumber already exist.
Note: Product.Porduct.Name also has an unique key constrain, but we don’t gonna handle this case, I’m gonna assume that Name and ProductNumber always go together and the pair never changes.
Summarizing, the steps for each record are:
- Check the existence of one ProductModel with Production.ProductModel.Name = ProductModelName.
- If exists, update the row data, if not exists insert a new row with the data.
- Get the ProductModelID from the recently updated/inserted row.
- Check the existence of one Product with Production.Product.ProductNumber = ProductName
- If exists update the row data, if not exists insert a new row with the data.
With all this, lets try some things!
Just run a stored procedure per row
This is the simplest way to get the job done, build a stored procedure that receives the data of one record as parameters.
We append this at the start of our SQL script:
USE AdventureWorks2019;
DROP PROCEDURE IF EXISTS #InsertProductsAndModels
GO
CREATE PROCEDURE #InsertProductsAndModels
@ProductModelName nvarchar(50),
@CatalogDescription xml,
@Instructions xml,
@ProductName nvarchar(50),
@ProductNumber nvarchar(25),
@SafetyStockLevel smallint,
@ReorderPoint smallint,
@StandardCost money,
@ListPrice money,
@DaysToManufacture int
AS
SET NOCOUNT ON;
IF (SELECT 1 FROM Production.ProductModel WHERE Name = @ProductModelName) = 1
UPDATE Production.ProductModel SET CatalogDescription=@CatalogDescription,Instructions=@Instructions WHERE Name=@ProductModelName;
ELSE
INSERT INTO Production.ProductModel (Name, CatalogDescription, Instructions) VALUES(@ProductModelName, @CatalogDescription, @Instructions);
DECLARE @MID int;
SELECT @MID = ProductModelID FROM Production.ProductModel WHERE Name = @ProductModelName;
IF (SELECT 1 FROM Production.Product WHERE ProductNumber = @ProductNumber) = 1
UPDATE Production.Product SET
Name=@ProductName,
SafetyStockLevel=@SafetyStockLevel,
ReorderPoint = @ReorderPoint,
StandardCost = @StandardCost,
ListPrice = @ListPrice,
DaysToManufacture = @DaysToManufacture,
SellStartDate = GETDATE(),
ProductModelID = @MID
WHERE ProductNumber = @ProductNumber;
ELSE
INSERT INTO Production.Product (Name, ProductNumber, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice, DaysToManufacture, SellStartDate, ProductModelID)
VALUES(@ProductName, @ProductNumber, @SafetyStockLevel, @ReorderPoint, @StandardCost, @ListPrice, @DaysToManufacture, GETDATE(), @MID);
GO
And the for each row that we want to insert:
EXEC #InsertProductsAndModels N'PMODEL0', null, null, N'P0', N'PCODE0', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL1', null, null, N'P1', N'PCODE1', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL2', null, null, N'P2', N'PCODE2', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL3', null, null, N'P3', N'PCODE3', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL4', null, null, N'P4', N'PCODE4', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL5', null, null, N'P5', N'PCODE5', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL6', null, null, N'P6', N'PCODE6', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL7', null, null, N'P7', N'PCODE7', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL8', null, null, N'P8', N'PCODE8', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL9', null, null, N'P9', N'PCODE9', 1000, 100, 0, 0, 1;
EXEC #InsertProductsAndModels N'PMODEL10', null, null, N'P10', N'PCODE10', 1000, 100, 0, 0, 1;
-- More...
For 50K rows took:
- 00:04:43.575 (283.575 seconds) inserting all.
- 00:04:48.593 (288.593 seconds) updating all.
This method can be good enough if you are inserting few rows from time to time, but when you are inserting a lot of rows at once is very slow. Databases like to work with tables and they are optimized for tables, using a stored procedure that works with one row at each time is a bit counterproductive.
So, lets find a better way.
Merge
We have a lot of rows that we have to insert/update in a very constrained way. But what if we create a very unconstrained temporary table first, insert all the data and then deal with our constrained insert/update later?
First, we declare a table variable and insert all the data with just very simple inserts:
USE AdventureWorks2019;
SET NOCOUNT ON;
DECLARE @tmp AS TABLE (
ProductModelName nvarchar(50),
CatalogDescription xml,
Instructions xml,
ProductName nvarchar(50),
ProductNumber nvarchar(25),
SafetyStockLevel smallint,
ReorderPoint smallint,
StandardCost money,
ListPrice money,
DaysToManufacture int)
INSERT INTO @tmp VALUES (N'PMODEL0', null, null, N'P0', N'PCODE0', 1000, 100, 0, 0, 1)
INSERT INTO @tmp VALUES (N'PMODEL1', null, null, N'P1', N'PCODE1', 1000, 100, 0, 0, 1)
INSERT INTO @tmp VALUES (N'PMODEL2', null, null, N'P2', N'PCODE2', 1000, 100, 0, 0, 1)
INSERT INTO @tmp VALUES (N'PMODEL3', null, null, N'P3', N'PCODE3', 1000, 100, 0, 0, 1)
INSERT INTO @tmp VALUES (N'PMODEL4', null, null, N'P4', N'PCODE4', 1000, 100, 0, 0, 1)
INSERT INTO @tmp VALUES (N'PMODEL5', null, null, N'P5', N'PCODE5', 1000, 100, 0, 0, 1)
-- More...
Now, we use MERGE, this command allows to modify a table in different ways depending on each record from a source. With this we can run an insert or update over the table checking if the key already exist. Merge is the optimal way to do this kind of insert/update when you have a lot of rows.
We run a Merge for the Production.ProductModel table and another for the Production.Product table. (The Production.Product table still needs the correct ProductModel’s IDs).
-- Insert or update all product models at once
MERGE Production.ProductModel AS destination
USING @tmp AS source
ON (destination.Name = source.ProductModelName)
WHEN MATCHED THEN
UPDATE SET CatalogDescription=source.CatalogDescription, Instructions=source.Instructions
WHEN NOT MATCHED THEN
INSERT (Name, CatalogDescription, Instructions) VALUES(source.ProductModelName, source.CatalogDescription, source.Instructions);
-- Insert or update all products at once
MERGE Production.Product AS destination
-- The using table has to contain a join with ProductModel in order to get the ProductModelId
USING (SELECT tmp.*, ppm.ProductModelId FROM @tmp AS tmp JOIN Production.ProductModel AS ppm ON tmp.ProductModelName = ppm.Name) AS source
ON (destination.ProductNumber = source.ProductNumber)
WHEN MATCHED THEN
UPDATE SET
Name=source.ProductName,
SafetyStockLevel=source.SafetyStockLevel,
ReorderPoint = source.ReorderPoint,
StandardCost = source.StandardCost,
ListPrice = source.ListPrice,
DaysToManufacture = source.DaysToManufacture,
SellStartDate = GETDATE(),
ProductModelID = source.ProductModelId
WHEN NOT MATCHED THEN
INSERT (Name, ProductNumber, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice, DaysToManufacture, SellStartDate, ProductModelID) VALUES(
source.ProductName,
source.ProductNumber,
source.SafetyStockLevel,
source.ReorderPoint,
source.StandardCost,
source.ListPrice,
source.DaysToManufacture,
GETDATE(),
source.ProductModelId);
SET NOCOUNT OFF;
For 50K rows took:
- 00:00:47.820 (47.820 seconds) inserting all.
- 00:00:46.159 (46.159 seconds) updating all.
Well, this is like 6 time faster than the previous method, but still a lot of time for just 50K rows. We are doing a lot of individual inserts, lets do better.
Merge with insert values
SQL Server allows to put up to 1000 value rows in a single insert, so lets do that:
USE AdventureWorks2019;
SET NOCOUNT ON;
DECLARE @tmp AS TABLE (
ProductModelName nvarchar(50),
CatalogDescription xml,
Instructions xml,
ProductName nvarchar(50),
ProductNumber nvarchar(25),
SafetyStockLevel smallint,
ReorderPoint smallint,
StandardCost money,
ListPrice money,
DaysToManufacture int)
INSERT INTO @tmp VALUES
(N'PMODEL0', null, null, N'P0', N'PCODE0', 1000, 100, 0, 0, 1),
(N'PMODEL1', null, null, N'P1', N'PCODE1', 1000, 100, 0, 0, 1),
(N'PMODEL2', null, null, N'P2', N'PCODE2', 1000, 100, 0, 0, 1),
(N'PMODEL3', null, null, N'P3', N'PCODE3', 1000, 100, 0, 0, 1),
-- Up to 1000
INSERT INTO @tmp VALUES
(N'PMODEL1000', null, null, N'P1000', N'PCODE1000', 1000, 100, 0, 0, 1),
(N'PMODEL1001', null, null, N'P1001', N'PCODE1001', 1000, 100, 0, 0, 1),
(N'PMODEL1002', null, null, N'P1002', N'PCODE1002', 1000, 100, 0, 0, 1),
(N'PMODEL1003', null, null, N'P1003', N'PCODE1003', 1000, 100, 0, 0, 1),
-- Up to 1000
-- More...
The MERGE part doesn’t change.
For 50K rows took:
- 00:00:25.658 (25.658 seconds) inserting all.
- 00:00:25.894 (25.894 seconds) updating all.
That’s an improvement!
You may think: Well, this INSERT VALUES think seems very direct, pretty sure is the fastest way to insert something into a table. RIGHT? RIGHT??? Let me show you something…
If we execute the same script again, it takes 8.212 seconds. WHY? When you execute anything in SQL server, it gets compiled and cached, then if you try to execute exactly the same thing it won’t need the compiling step. This is very useful for complex selects or procedures. But the cache is useless for this kind of inserts as you usually insert different data each time.
The worrying part is: Why did it take almost 17 seconds to compile? This is a pretty simple statement.
I recommend you to take a look at the point 16 of this article, where explains the problem. Turns out that the compilation grows in a non-linear way for this kind of statement. Which doesn’t make any sense for me, Microsoft should fix this.
Knowing that the compilation of INSERT VALUES is very bad. We can find a way to avoid it.
Merge with insert exec
The previously mentioned article shows a hacky way to insert a lot of values without the compilation time hit.
This way is using an INSERT EXEC and the EXEC part receives an string with SELECTS for each individual row that we want to insert.
USE AdventureWorks2019;
SET NOCOUNT ON;
DECLARE @tmp AS TABLE (
ProductModelName nvarchar(50),
CatalogDescription xml,
Instructions xml,
ProductName nvarchar(50),
ProductNumber nvarchar(25),
SafetyStockLevel smallint,
ReorderPoint smallint,
StandardCost money,
ListPrice money,
DaysToManufacture int)
INSERT @tmp
EXEC('
SELECT N''PMODEL0'', null, null, N''P0'', N''PCODE0'', 1000, 100, 0, 0, 1
SELECT N''PMODEL1'', null, null, N''P1'', N''PCODE1'', 1000, 100, 0, 0, 1
SELECT N''PMODEL2'', null, null, N''P2'', N''PCODE2'', 1000, 100, 0, 0, 1
SELECT N''PMODEL3'', null, null, N''P3'', N''PCODE3'', 1000, 100, 0, 0, 1
SELECT N''PMODEL4'', null, null, N''P4'', N''PCODE4'', 1000, 100, 0, 0, 1
SELECT N''PMODEL5'', null, null, N''P5'', N''PCODE5'', 1000, 100, 0, 0, 1
-- More...
SELECT N''PMODEL49999'', null, null, N''P49999'', N''PCODE49999'', 1000, 100, 0, 0, 1');
The MERGE part doesn’t change.
For 50K rows took:
- 00:00:11.397 (11.397 seconds) inserting all.
- 00:00:10.341 (10.341 seconds) updating all.
This method was 2.2 times faster than the previous one and 25 times faster than the first one. This method is the fastest way that i found (with the restriction of having to generate a self contained SQL script). If you don’t have that restriction there are better ways that are usually proposed, I’m gonna show 2 of them.
NOTE: I also tried to generate an xml string with all the data, extract all the data with a select and then use the merge. But I didn’t bother to put more about it here, it was too cumbersome and it was just slightly better than the insert values method. insert exec still better.
I’m kind of disappointed, that this is the best I’ve got. In the next point you will see why.
BULK INSERT
BULK INSERT is one of the recommended ways to insert a lot of data into a database. This method requires a file (for example a .csv) with all the data, and that file must be reachable from the server, this usually means that you have to copy manually the file to the server before executing anything.
The SQL code is mostly the same as before but uses BULK INSERT to put all the data into a temporary table:
USE AdventureWorks2019;
SET NOCOUNT ON;
DROP TABLE IF EXISTS #tmp
CREATE TABLE #tmp (
ProductModelName nvarchar(50),
CatalogDescription xml,
Instructions xml,
ProductName nvarchar(50),
ProductNumber nvarchar(25),
SafetyStockLevel smallint,
ReorderPoint smallint,
StandardCost money,
ListPrice money,
DaysToManufacture int)
-- Bulk insert all the data into a temporary table
BULK INSERT #tmp FROM '/bulk_insert.csv' WITH (FORMAT = 'CSV');
-- Insert or update all product models at once
MERGE Production.ProductModel AS destination
USING #tmp AS source
ON (destination.Name = source.ProductModelName)
WHEN MATCHED THEN
UPDATE SET CatalogDescription=source.CatalogDescription, Instructions=source.Instructions
WHEN NOT MATCHED THEN
INSERT (Name, CatalogDescription, Instructions) VALUES(source.ProductModelName, source.CatalogDescription, source.Instructions);
-- Insert or update all products at once
MERGE Production.Product AS destination
-- The using table has to contain a join with ProductModel in order to get the ProductModelId
USING (SELECT tmp.*, ppm.ProductModelId FROM #tmp AS tmp JOIN Production.ProductModel AS ppm ON tmp.ProductModelName = ppm.Name) AS source
ON (destination.ProductNumber = source.ProductNumber)
WHEN MATCHED THEN
UPDATE SET
Name=source.ProductName,
SafetyStockLevel=source.SafetyStockLevel,
ReorderPoint = source.ReorderPoint,
StandardCost = source.StandardCost,
ListPrice = source.ListPrice,
DaysToManufacture = source.DaysToManufacture,
SellStartDate = GETDATE(),
ProductModelID = source.ProductModelId
WHEN NOT MATCHED THEN
INSERT (Name, ProductNumber, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice, DaysToManufacture, SellStartDate, ProductModelID) VALUES(
source.ProductName,
source.ProductNumber,
source.SafetyStockLevel,
source.ReorderPoint,
source.StandardCost,
source.ListPrice,
source.DaysToManufacture,
GETDATE(),
source.ProductModelId);
SET NOCOUNT OFF;
And /bulk_insert.csv looks like:
"PMODEL0",,,"P0","PCODE0",1000,100,0,0,1
"PMODEL1",,,"P1","PCODE1",1000,100,0,0,1
"PMODEL2",,,"P2","PCODE2",1000,100,0,0,1
"PMODEL3",,,"P3","PCODE3",1000,100,0,0,1
"PMODEL4",,,"P4","PCODE4",1000,100,0,0,1
More...
For 50K rows took:
- 00:00:03.013 (03.013 seconds) inserting all.
- 00:00:03.526 (03.526 seconds) updating all.
This method is more than 3 times faster than INSERT EXEC and if we take a look at the actual execution plan:
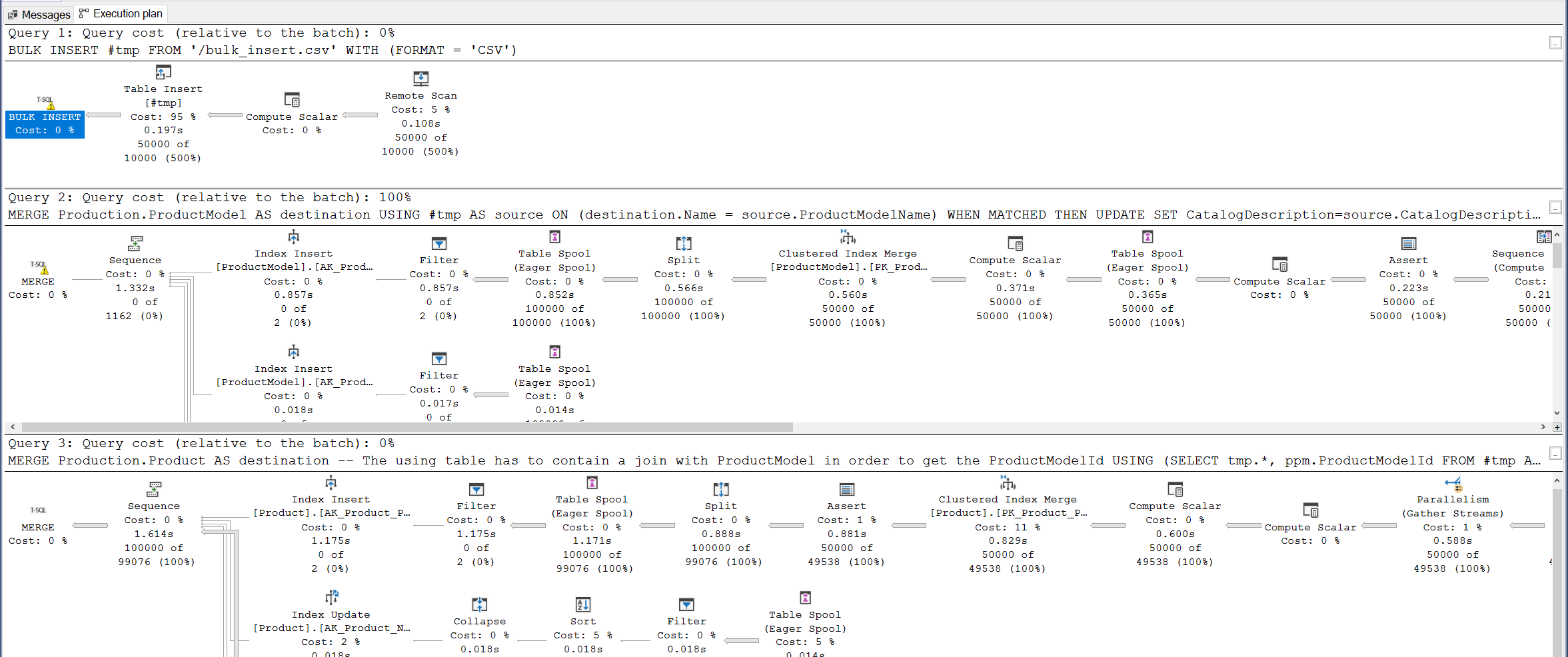
Most of the time is in the actual MERGEs, the BULK INSERT is just free. This means that all the other methods were struggling in doing something that SQL server can do instantly.
Using Table Valued Parameters
The previous strategy allows you to execute the SQL script very fast with the caveat that you have to previously copy one file to the server.
The method that I’m going to show now, doesn’t need to previously copy a file, with the caveat that doesn’t allows you to execute a SQL file at all. This requires write a program in C# or any other language with a library that supports Table Valued Parameters.
You can learn about table valued parameters here and here.
This is the small example that I wrote:
using System;
using System.Data;
using System.Data.SqlTypes;
using System.Data.SqlClient;
using System.Collections.Generic;
using Microsoft.SqlServer.Server;
class MainTVP {
private static void Main() {
string drop_table_type_cmd = @"
DROP TYPE IF EXISTS InsertProductsAndModelsType
";
string setup_table_type_cmd = @"
CREATE TYPE InsertProductsAndModelsType
AS TABLE (
ProductModelName nvarchar(50),
CatalogDescription xml,
Instructions xml,
ProductName nvarchar(50),
ProductNumber nvarchar(25),
SafetyStockLevel smallint,
ReorderPoint smallint,
StandardCost money,
ListPrice money,
DaysToManufacture int)
";
string merge_data_cmd = @"
SET NOCOUNT ON;
-- Insert or update all product models at once
MERGE Production.ProductModel AS destination
USING @tvp AS source
ON (destination.Name = source.ProductModelName)
WHEN MATCHED THEN
UPDATE SET CatalogDescription=source.CatalogDescription, Instructions=source.Instructions
WHEN NOT MATCHED THEN
INSERT (Name, CatalogDescription, Instructions) VALUES(source.ProductModelName, source.CatalogDescription, source.Instructions);
-- Insert or update all products at once
MERGE Production.Product AS destination
-- The using table has to contain a join with ProductModel in order to get the ProductModelId
USING (SELECT tvp.*, ppm.ProductModelId FROM @tvp AS tvp JOIN Production.ProductModel AS ppm ON tvp.ProductModelName = ppm.Name) AS source
ON (destination.ProductNumber = source.ProductNumber)
WHEN MATCHED THEN
UPDATE SET
Name=source.ProductName,
SafetyStockLevel=source.SafetyStockLevel,
ReorderPoint = source.ReorderPoint,
StandardCost = source.StandardCost,
ListPrice = source.ListPrice,
DaysToManufacture = source.DaysToManufacture,
SellStartDate = GETDATE(),
ProductModelID = source.ProductModelId
WHEN NOT MATCHED THEN
INSERT (Name, ProductNumber, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice, DaysToManufacture, SellStartDate, ProductModelID) VALUES(
source.ProductName,
source.ProductNumber,
source.SafetyStockLevel,
source.ReorderPoint,
source.StandardCost,
source.ListPrice,
source.DaysToManufacture,
GETDATE(),
source.ProductModelId);
";
// Table structure in C#
SqlMetaData[] InsertProductsAndModelsType =
{
new SqlMetaData("ProductModelName", SqlDbType.NVarChar, 50),
new SqlMetaData("CatalogDescription", SqlDbType.Xml),
new SqlMetaData("Instructions", SqlDbType.Xml),
new SqlMetaData("ProductName", SqlDbType.NVarChar, 50),
new SqlMetaData("ProductNumber", SqlDbType.NVarChar, 25),
new SqlMetaData("SafetyStockLevel", SqlDbType.SmallInt),
new SqlMetaData("ReorderPoint", SqlDbType.SmallInt),
new SqlMetaData("StandardCost", SqlDbType.Money),
new SqlMetaData("ListPrice", SqlDbType.Money),
new SqlMetaData("DaysToManufacture", SqlDbType.Int)
};
// Populate all the data
var productsAndModelsData = new List<SqlDataRecord>();
for (int i = 0; i < 50000; i+=1) {
var currentRow = new SqlDataRecord(InsertProductsAndModelsType);
var productModelName = System.String.Format("PMODEL{0}", i);
var productName = System.String.Format("P{0}", i);
var productNumber = System.String.Format("PCODE{0}", i);
currentRow.SetValues(productModelName, new SqlXml(), new SqlXml(), productName, productNumber, (Int16)(1000), (Int16)(100), new SqlMoney(0), new SqlMoney(0), (Int32)(1));
productsAndModelsData.Add(currentRow);
}
// Start the connection
SqlConnection cn = new SqlConnection("server=tcp:127.0.0.1,1433;Initial Catalog=AdventureWorks2019;Integrated Security=false; User=sa; Password=1234ABC?");
cn.Open();
var sw = new System.Diagnostics.Stopwatch();
sw.Start();
// Setup the type in the database
SqlCommand setup_cmd = new SqlCommand(drop_table_type_cmd, cn);
setup_cmd.ExecuteNonQuery();
setup_cmd = new SqlCommand(setup_table_type_cmd, cn);
setup_cmd.ExecuteNonQuery();
// Insert all the data
SqlCommand insertCommand = new SqlCommand(merge_data_cmd, cn);
SqlParameter tvpParam = insertCommand.Parameters.AddWithValue("@tvp", productsAndModelsData);
tvpParam.SqlDbType = SqlDbType.Structured;
tvpParam.TypeName = "InsertProductsAndModelsType";
insertCommand.ExecuteNonQuery();
cn.Close();
sw.Stop();
System.Console.WriteLine("Elapsed={0}",sw.Elapsed);
}
}
I’m not going to give more details about how it works, you can take a look at this great article.
For 50K rows took:
- 00:00:03.303 (03.303 seconds) inserting all.
- 00:00:03.733 (03.733 seconds) updating all.
This takes mostly the same as the BULK INSERT approach but with a different set of trade-offs.
Summary
| Method | 50000 Inserts(s) | 50000 Updates(s) |
|---|---|---|
| Stored procedure per row | 283.575 | 288.593 |
| Merge | 47.820 | 46.159 |
| Merge with insert values | 25.658 | 25.894 |
| Merge with insert exec | 11.397 | 10.341 |
| BULK INSERT | 03.013 | 03.52 |
| Table Valued Parameters | 03.303 | 03.733 |
And that’s it! If I got something wrong or you know better ways to do this, send me an email to contact@tano.xyz, I will happily update the article.
Publish date:
Modified date: